

ปัจจุบันในคอมพิวเตอร์ของเรา หรือกระทั่งสมาร์ตโฟนเองก็สามารถที่จะพิมพ์ภาษาไทยได้อย่างง่ายดายแล้ว แต่รู้หรือไม่ว่ากว่าที่คอมพิวเตอร์ของเราจะพัฒนาจนสามารถพิมพ์ภาษาไทยได้นั้น ต้องผ่านการพัฒนามามากมายหลายอย่างเลย แล้วภาษาไทยในคอมพิวเตอร์นี้เกิดขึ้นมาได้อย่างไรกันล่ะ ?
เรื่องราวทั้งหมดต้องเล่าย้อนไปจนถึงปี 2510 ที่เครื่องคอมพิวเตอร์ระดับเมนเฟรมของ IBM สามารถอ่านบัตรเจาะรูรหัสภาษาไทย (EBCDIC Code) และพิมพ์รายงานไทย – อังกฤษได้ นับตั้งแต่นั้นคอมพิวเตอร์ที่ใช้ภาษาไทยยี่ห้ออื่น ๆ ก็ทยอยเกิดขึ้นเรื่อยมา อย่างเช่นเครื่องคอมพิวเตอร์ UNIVAC 9400 เมื่อปี 2513 ที่อ่านบัตรประมวลผลแล้วอ่านผลเป็นภาษาไทยได้

หลังจากนั้นมา คอมพิวเตอร์แบรนด์ต่าง ๆ ในสมัยนั้นก็รองรับภาษาไทยมากยิ่งขึ้น เช่นคอมพิวเตอร์ของ Control Data ในปี 2515 และของ Wang ในปี 2518 จนถึงปี 2527 ที่ไมโครคอมพิวเตอร์ทุกยี่ห้อในประเทศไทย ใช้งานกับข้อมูลภาษาไทยได้ พิมพ์ภาษาไทยได้ และเริ่มมีผู้ผลิตการ์ดจอในยุคเริ่มต้น ที่แสดงผลตัวหนังสือได้ 25 บรรทัด อย่างเช่น Hercules Graphics Card (HGC) ที่มีคนไทยเป็นผู้ร่วมสร้างชื่อ ‘Van Suwannukul’ ในปี 2525

หลังจากนั้น ภาษาไทยก็ได้ถูกกำหนดตำแหน่งอักขระของรหัสแอสกี (ASCII – American standard code for information interchange) เอาไว้ในมาตรฐาน ISO 646-1983 ซึ่งได้กำหนดโค้ดตัวหนังสือแบบ 7 bit กล่าวคือ สามารถใส่ตัวอักษรได้ 128 ตัว (ทำให้มีภาษาไทยในนั้นได้) เมื่อปี 2526 ดังภาพด้านล่าง
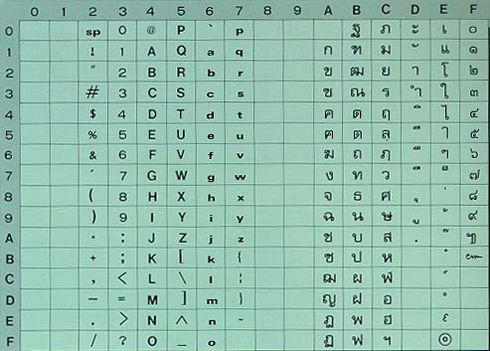
ซึ่งตำแหน่งของรหัส ASCII นั้นจะซ้อนกันไปในแต่ละภาษา ทำให้ต้องกำหนดว่าเป็นรหัส ASCII ของภาษาไหน จนนำไปสู่การสร้างระบบ Unicode ต่อมา เรื่องนั้นเราจะเล่าถึงต่อไปเมื่อมีโอกาส
แม้จะมีไมโครคอมพิวเตอร์ที่พิมพ์ภาษาไทยได้หลายแบรนด์มาก แต่ก็มีปัญหาด้านรหัสภาษาไทย (Character Codes for Computers) ในคอมพิวเตอร์แต่ละแบรนด์ ที่แตกต่างกันกว่า 20 รูปแบบ ทำให้เกิดปัญหาในการพัฒนาซอฟต์แวร์ขึ้น เนคเทค สวทช. กับมหาวิทยาลัยธรรมศาสตร์ ก็เลยจัดโครงการวิจัยด้านซอฟต์แวร์ร่วมกับหน่วยงานต่าง ๆ ผ่านกลุ่ม Thai API Consortium (TAPIC) จนออกมาเป็น ข้อกำหนดสำหรับอุตสาหกรรมคอมพิวเตอร์ไทยใน พ.ศ. 2529 – 2534 หลายฉบับเลย โดย 1 ในข้อกำหนดที่รวมไว้เป็นลายลักษณ์อักษรก็คือ มอก.620-2533 ที่ได้กำหนด ‘รหัสสำหรับอักขระไทยที่ใช้กับคอมพิวเตอร์’ ของรหัส ASCII ภาษาไทย ตาม ISO 646-1983 และ EBCDIC Code ภาษาไทยเอาไว้ เพื่อกำหนดมาตรฐานของโค้ดภาษาไทยทั้งสองแบบให้ชัดเจน
นอกจากนั้น หนึ่งในข้อกำหนดที่สำคัญที่สุด ก็คือในปี 2534 ทาง TAPIC ได้ออก ‘ร่าง มาตรฐานผลิตภัณฑ์อุตสาหกรรมเทคโนโลยีสารสนเทศ มาตรฐานซอฟต์แวร์สำหรับภาษาไทย’ หรือชื่อเล่นที่ทาง TAPIC ตั้งให้ว่า ‘วทท 2.0’ (ย่อมาจาก วิ่งทั่วไทย) ที่เกิดขึ้นมาเพื่อยุติปัญหาด้านรหัสภาษาไทยที่แตกต่างกัน โดยกำหนดให้เป็นมาตรฐานวิธีใช้ API เดียวกันในการพัฒนาซอฟต์แวร์ ให้ภาษาไทยนั้นมีการรับเข้า (Input) การประมวลผล (Processing) และการแสดงผล (Output) ที่เหมือนกัน ซึ่ง วทท 2.0 ได้นำเอา มอก.620-2533 มาเป็นพื้นฐานในการร่างมาตรฐานนี้อีกที
ทางสำนักงานพัฒนาวิทยาศาสตร์และเทคโนโลยีแห่งชาติ (สวทช.) ได้อธิบายเพิ่มเติมไว้ว่า “วทท 2.0 นั้นถูกนำไปใช้พัฒนาระบบภาษาไทยของ MS-DOS, Windows ของไมโครซอฟต์ (Microsoft) ทำให้ระบบ MS-DOS version 6.0 และ Windows 3.0 เป็นต้นมา มีคุณสมบัติตรงกับ วทท.2.0 ซึ่งในขณะนั้นเป็นเพียงร่างมาตรฐานสำหรับประเทศไทยเท่านั้น”
ซึ่งหลังจากที่ทาง TAPIC ได้ผลักดันการออกมาตรฐาน วทท 2.0 นี้มาอย่างยาวนาน มาตรฐาน วทท 2.0 ก็ถูกประกาศใช้ในราชกิจจานุเบกษา ประกาศกระทรวงอุตสาหกรรม ฉบับที่ 2485/2542 เรื่อง กำหนดมาตรฐานผลิตภัณฑ์อุตสาหกรรม อักขรวิธีภาษาไทยสำหรับคอมพิวเตอร์ ออกมาเป็น มอก.1566-2541 ที่เป็นมาตรฐานในการใช้ภาษาไทยในคอมพิวเตอร์ให้เป็นรูปแบบเดียวกันนั่นเอง
แต่ว่า Windows มีมาตั้งแต่เวอร์ชัน 1.0 ซึ่งออกมาตั้งแต่ปี 2528 นี่นา แล้วก่อนที่ไมโครซอฟต์จะใส่ภาษาไทยเข้ามา เราพิมพ์ภาษาไทยได้อย่างไรกันล่ะ ?
ต่อไปเราอยากจะให้ทุกคนได้รู้จักกับ ‘หมอจิมมี่’ หรือ ‘นายแพทย์ภาณุทัต เตชะเสน’ กัน

หมอจิมมี่นั้นได้แฮ็ก (Hack) Windows 1.0 ในช่วงที่ Windows 1.0 ยังออกมาได้ไม่นานนัก (ปี 2528 – 2529) เขาได้เรียนรู้การใช้ DDK (Device Development Kit) และทำภาษาไทยสำเร็จด้วยการเขียน display driver ใหม่ทั้งตัว แต่ไม่ได้มีการวางขาย เนื่องจากตอนนั้นหมอจิมมี่ยังไม่สามารถทำให้โปรแกรมนั้นใช้งานภาษาไทยได้ดีพอจะขายได้
ต่อมา เมื่อ Windows 2.0 ออกมาในปี 2530 หมอจิมมี่ก็เห็นว่ามีโปรแกรม Microsoft Write (ซึ่งเป็นโปรแกรม Word Processor ที่มากับ Windows) โดยที่ยังมี feature ไม่มากนัก หมอจิมมี่ก็เลยเขียนเลียนแบบโปรแกรมนั้นทั้งตัว ออกมาเป็นโปรแกรม “tofWrite” ออกมา tof โดย tof นั้นย่อมาจาก Three-One-Five หรือ 315 ซึ่งเป็นชื่อบริษัท มาจากเลขที่ 315 ถนนสีลม ที่ตั้งแรกของบริษัท ซึ่งเป็นเครือของอาคเนย์ประกันภัย
โปรแกรม tofWrite นั้นเป็น WYSIWYG (What You See Is What You Get) word processor (เห็นอย่างไร พิมพ์ออกมาได้อย่างนั้น) ภาษาไทยตัวแรกของ IBM PC ตั้งราคาขายที่ 15,000 บาท (เมื่อ 30 กว่าปีที่แล้ว) หมอจิมมี่บอกว่า ตัวโปรแกรมขายดีเป็นเทน้ำเทท่าเลย
จากนั้น Windows 3.0 ออกมาในปี 2533 หมอจิมมี่เลยได้ทำภาษาไทยให้โปรแกรมต่าง ๆ ใช้ภาษาไทยได้ จึงออกมาเป็นโปรแกรม ThaiWin 1.0 โดยวางขายในราคา 15,000 บาท และมีรุ่นโปรที่สามารถเปิด Page Maker ได้ด้วย ในราคา 35,000 บาท

บริษัท 315 ที่หมอจิมมี่อยู่นั้น ก็วางขายได้อย่างดี ขายโปรแกรม ThaiWin ได้มาก แต่แล้ววันหนึ่ง ทาง Microsoft ก็ได้มาคุยกับทางบริษัท 315 ด้วย บอกว่าจะซื้อลิขสิทธิ์ของโปรแกรม ThaiWin ไปขายคู่กับ Windows จึงได้มาขอตัวอย่างโปรแกรมไปดู หมอจิมมี่เลยให้ไป แล้วก็กลับมาเจรจา บอกว่า ไมโครซอฟต์ขอซื้อลิขสิทธิ์โปรแกรมในราคาชุดละ 5 เหรียญ บอกว่าไมโครซอฟต์จะ “Technology Transfer” (หรือปรับโอนเทคโนโลยี ให้สามารถใช้โปรแกรมของเดิม ให้ใช้ Windows รุ่นใหม่) ให้ด้วย แต่ทางหมอจิมมี่ กับเพื่อนร่วมงานของเขาที่บริษัท 315 ตัดสินใจไม่รับข้อเสนอ
ทำให้ Windows 3.1 ที่ออกมาในปี 2535 นั้น มีภาษาไทยตามที่คาด (โดยไม่ได้ใช้โปรแกรม ThaiWin เลย) และได้ใช้มาตรฐาน วทท. 2.0 ด้วย แต่หมอจิมมี่บอกว่า โปรแกรม ThaiWin 3.1 ยังขายดีอยู่ บริษัท 315 ยังคงรอดต่อไป แต่ก็รู้ดีว่าไมโครซอฟต์ต้องอัปเกรด จนสามารถใช้แทน ThaiWin ได้แน่ ซึ่งหลังจากไมโครซอฟต์ได้ทำการอัปเดตหลายครั้ง โปรแกรม ThaiWin ก็ถึงจุดจบที่ยอดขายหายไป ไม่มีใครต้องใช้ระบบภาษาไทยสำหรับ Windows ที่มีภาษาไทยอยู่แล้วอีก
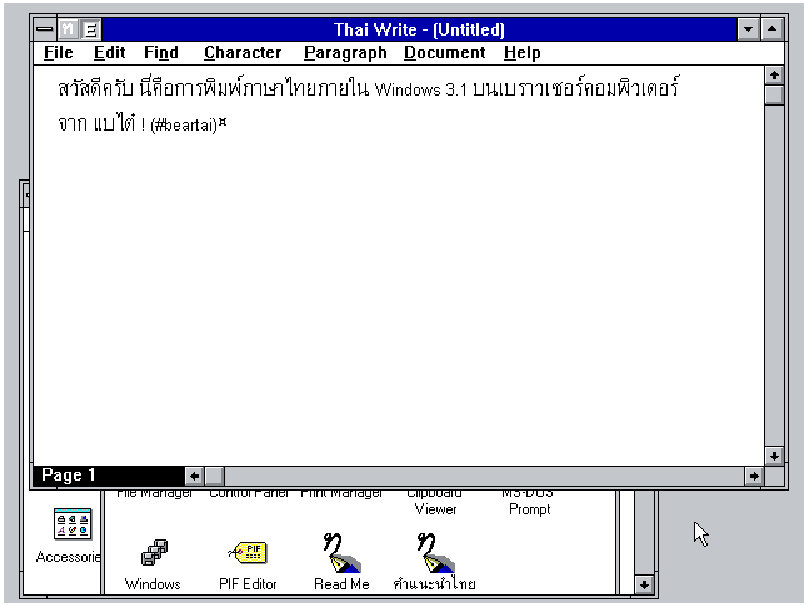
หลังจากนั้น ภาษาไทยก็เป็นอีก 1 ภาษาที่สามารถใช้งานได้ใน Windows ตั้งแต่นั้นเป็นต้นมา จนถึงปัจจุบัน
ที่มา : สวทช. , หนังสือ คอมพิวเตอร์กับภาษาไทย : การพัฒนามาตรฐานเบื้องต้น สำหรับเทคโนโลยีสารสนเทศของไทย (ออนไลน์) ผ่าน สวทช., มูลนิธิโครงการสารนุกรมไทยสำหรับเยาวชน, ราชกิจจานุเบกษา, นายแพทย์ภาณุทัต เตชะเสน