

สถาบัน Intelligent Computing ของ Alibaba ได้เปิดตัว ‘EMO’ (Emote Portrait Alive) โมเดล AI ที่สามารถสร้างวิดีโอร้องเพลงหรือการพูดได้จากภาพเพียงภาพเดียว
สำหรับ EMO เป็นเป็นเทคโนโลยี ‘Expressive Audio-Driven Portrait-Video Generation Framework’ ที่เราสามารถใส่รูปกับเสียงเข้าไป แล้วตัว AI จะเปลี่ยนภาพนิ่งใบนั้นเป็นวิดีโอที่ขยับพูดคุยหรือร้องเพลงได้ตรงกับเสียงที่เราใส่เข้าไปนั้นเองครับ แถมไม่ได้เป็นการขยับปากให้ตรงกับเสียงเฉย ๆ แต่ยังมีการแสดงสีหน้าอารมณ์ที่สมจริงด้วย โดยสามารถสร้างวิดีโอที่ความยาวสูงสุด 1 นาที 30 วินาที
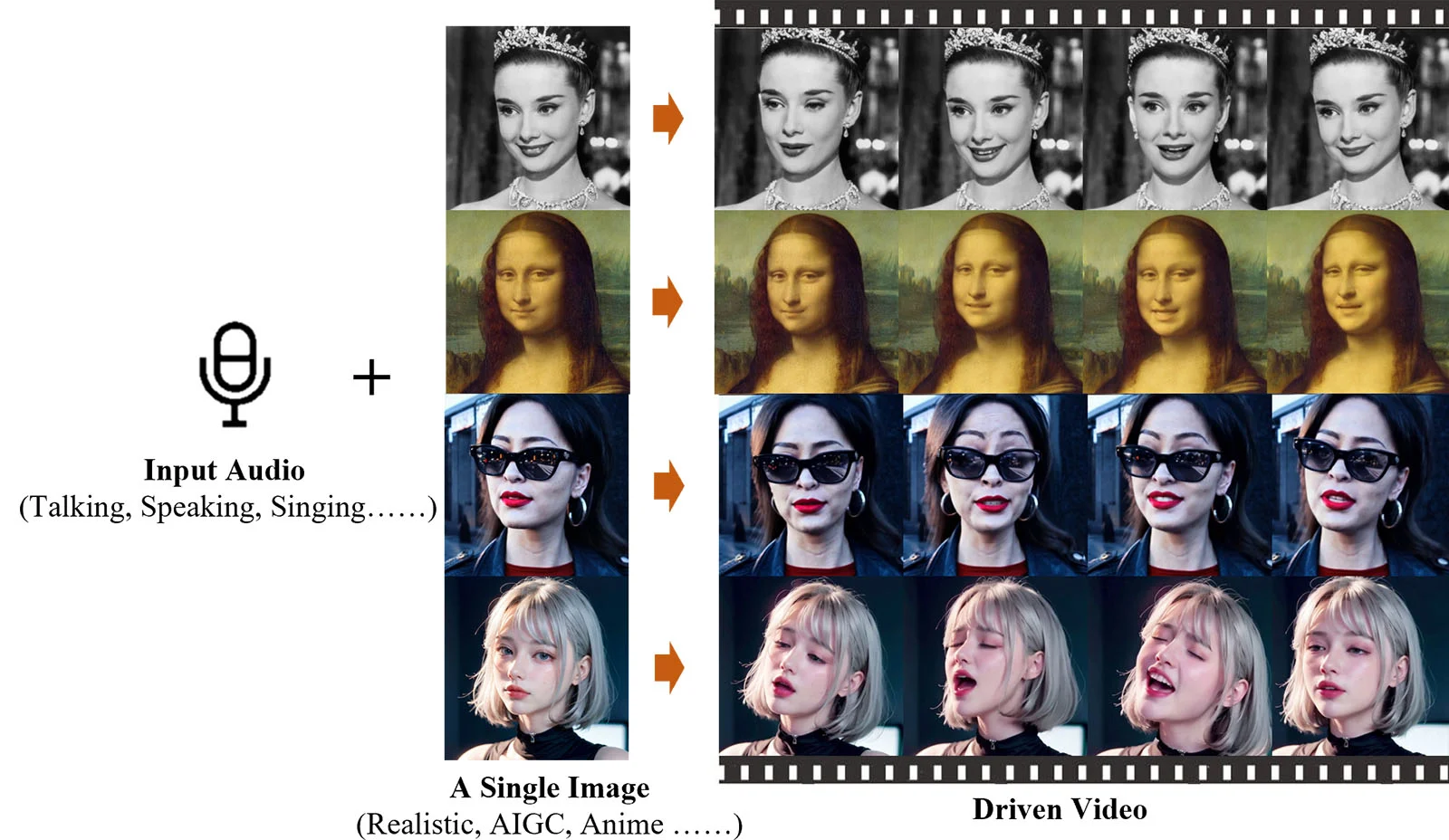
ตัว EMO ยังรองรับการใช้งานในหลากหลายภาษา และใช้งานได้กับสไตล์ศิลปะหลายหลายประเภทเลยครับ ไม่ว่าจะเป็นภาพถ่าย ภาพวาด หรือแม้กระทั้งอนิเมะ และ 1 ในตัวอย่างที่ทีมทำออกมาโชว์ดูเหมือนเป็นการข้ามค่ายหน่อย ๆ ก็คือการนำภาพผู้หญิงใส่แว่นกันแดดในการเปิดตัวของ OpenAi ‘Sora’ มาร้องเพลง ‘Don’t Start Now’ ของ ดูอา ลิปา (Dua Lipa)
รายละเอียดการวิจัยทั้งหมดของ EMO สามารถดูได้ที่เว็บไซต์ Github พร้อมกับบทความวิจัยที่เกี่ยวข้องที่ ArXiv ครับ